추상 자료형 (ADT) - 다음과 같은 연산으로 각 키에 따른 항목 집합을 유지
- insert(item) : 집합에 항목 추가
- delete(item) : 집합에서 항목 제거
- search(key) : 존재할 경우 키와 항목 변환
항목은 각자의 키를 가지고 있다고 가정(또는 새 것을 삽입할 때 옛 것을 덮어 씌움)
균형 이진 탐색 트리는 연산 하나 당 O(log n) 시간 소요 (그 다음 큰 수 탐색과 같은 정밀하지 않은 탐색도 가능)
목표 : 연산 하나 당 O(1) 시간
동기
딕셔너리는 컴퓨터 과학 분야에서 가장 많이 쓰이는 자료구조이다.
- 문서 거리 문제 : 단어 세기 & 내적
- 데이터베이스 구현 :
- 영어 단어 -> 정의
- 영어 단어 : 철자 교정
- 단어 -> 그 단어를 포함한 모든 웹페이지
- 사용자 이름 -> 계정 객체
- 컴파일러 & 인터프리터 : 이름 -> 변수
- 네트워크 라우터 : IP 주소 -> 랜선
- 네트워크 서버 : 포트 번호 -> 소켓/앱
- 가상 메모리 : 가상 주소 -> 물리적 주소
그 외에도 간접적으로 해싱을 쓰는 경우
- 부분 문자열 탐색 (grep, Google)
- 염기 공통성 (DNA)
- 파일 또는 디렉토리 동기화 (rsync)
- 암호학 : 파일 변환 & 식별
딕셔너리 접근법 : 직접 접근 테이블
1.키는 반드시 음이 아닌 정수여야 한다. 2.넓은 키의 범위 -> 큰 공간 필요 ex) 2^256 인 키는 좋지 않다.
1번에 대한 해결 법 : 키를 정수로 “프리해시”
- 키가 유한하기 때문에 이론적으로 가능 ⇒ 키의 집합을 셀 수 있다.
- 파이썬: 해시(객체) (사실 “해시”는 적절한 명칭이 아님. “프리 해시”가 정확한 표현) 객체는 숫자, 문자열, 튜플 등 또는 __hash__가 구현된 객체가 될 수 있다. (기본값 = id = 메모리 주소)
- 정리에 의해, x = y ⇔ hash(x) = hash(y)
- 파이썬은 실용성을 위해 경험적인 방법을 일부 적용했다. : 예로, hash(‘\0B ’) = 64 = hash(‘\0\0C’)
- 테이블에서 객체의 키는 바뀌어서는 안된다. (바뀌면 더 이상 찾을 수 없다.)
- 리스트와 같은 가변 객체는 안된다.
충돌을 다루는 방법
if h(ki) = h(kj)
체이닝 테이블의 각 슬롯마다 충돌하는 원소들의 연결 리스트를 만듬
- 탐색 시 리스트 전체인 T[h(key)] 를 흝어야 한다.
- 최악의 경우 : 모든 n개의 키가 같은 슬롯에 있는 경우 => 연산 당 Θ(n)
간단 균일 해싱
모든 키는 테이블의 아무 슬롯에나 해시될 가능성을 동등하게 가지고 있다. 각 키의 해시는 독립적으로 다른 키가 해시되었는지와 상관없다.
let n = 테이블에 저장된 키의 개수 m = 테이블의 슬롯 개수 적재율 α = n/m 슬롯당 예상되는 키의 개수 = 체인의 예상되는 길이
탐색의 예상되는 실행 시간이 Θ(1+α)라는 의미한다. — 1은 해시 함수를 적용하고 슬롯에 임의 접근하는 것을 의미하는 반면 α는 리스트를 탐색하는 것을 의미한다. α = O(1)이면 O(1)이 된다. 즉, m = Ω(n).
해시함수
위와 같은 성능을 달성하는 방법 3가지
- 나머지 연산법 h(k) = k mod m
m이 2의 제곱이나 10의 제곱에 가까이 있지 않은 소수일 경우 실용적이다. (이때 낮은 자릿수나 비트에 따라 다르다.)
단점 : 소수를 찾는것이 편리하지 않고, 나머지 연산법은 느리다.
- 곱셈 방법 h(k) = [(a-k) mod 2 w] » (w-r) a는 임의값, k는 w 비트, 그리고 m=2^r이다.
a가 홀수 이고 2^w-1 < a < 2^w 그리고 a가 2^w-1 또는 2^w에 너무 가깝지 않아야 이 방법이 실용적이다.
곱셈과 비트 추출은 나눗셈보다 빠르다.
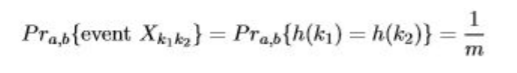

유니버설 해싱 예 : h(k) = [(ak+b) mod p] mod m, a와 b는 임의 값 ∈{0,1,…p−1}, 그리고 p는 소수 (> |U|).
이 말인 즉, 최악의 경우에는 키가 k1 ≠ k2 이다. (h의 선택 a, b에 의해):
출처