계산모델이 규정하는것
- 각 알고리즘이 할 수 있는 연산
- 각 연산의 비용 (시간, 공간)
- 알고리즘의 비용 = 연산 비용의 합
임의 접근 머신(RAM)
• 거대한 배열로 만들어진 임의 접근 머신 (RAM)
• Θ(1) 레지스터 (각 1개의 워드)
• Θ(1) 시간 안에 할 수 있는 일
– 레지스터 ri 에 있는 워드를 레지스터 rj 으로 불러오기
– 레지스터에서 (+, −, ∗, /, &, |, ˆ) 계산
– 레지스터 rj 를 ri 에 있는 메모리에 저장
포인터 머신
• 동적 할당된 객체 (네임드 튜플)
• 객체는 O(1)개의 필드를 갖는다.
• 필드 = 워드 (e.g., 정수) 또는 객체/널을 가리키는 포인터 (a.k.a. 참조)
• RAM보다 약하다 (RAM으로 구현 가능)
문서거리 문제 : 유사한 문서 탐색이나 중복과 표절 발견, 웹 검색에 적용
정의
- 단어 = 영어와 숫자로 이루어진 문자열
- 문서 = 단어의 나열(공백, 문장, 부호 등 무시)
공통으로 갖는 단어를 통해 거리를 정의
문서 D는 벡터, D[w] = 단어 , w의 등장 횟수
첫번째 시도, 문서 거리의 정의
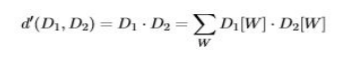
문서의 규모에 따라 변할 수 있다. 따라서 단어의 개수로 정규화 한다.
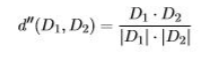
기하학적 해석(재구성)
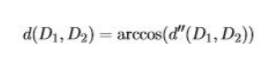
문서 거리는 두 벡터 사이의 각도이다. 0 도는 두 문서가 같다는 것을 의미, 90도는 공통 단어가 없다는 것을 의미
문서거리 알고리즘
- 각 문서를 단어들로 쪼갠다.
- 단어 빈도를 센다.(문서 벡터)
- 내적을 계산 한다. (& 나눈다.)

출처